想在分析研究 javascript code 之前想來探討一下這個網頁是如何被瀏覽器讀取的,這樣以後寫網站才能把網頁寫的更好,速度更快
當瀏覽器從你的伺服器,或者是從 Todo List 下載 html 到瀏覽器的時候,瀏覽器會這樣執行
parse 這份 html,render tree

圖片取自when-does-parsing-html-dom-tree-happen
有人在發了這個問題When does parsing HTML DOM tree happen?
我覺得這個題問滿有趣的,而且問得很好,想揪家一起讀他們的對答 (讀者:其實你想混這篇對吧!!)
是說瀏覽器只有在 DOMTree 被解析出來和 CSSOM 被創造出來才開始畫畫的對吧?
但有人說把 <script> 放到 <body> 後面才是最好的做法,這樣做的話頁面會先被宣染,才會去下載網頁需要的資源
他說他認為 <script> 都是在 DOMTree 裡面,所以 <script> 裡的資源要先被下載完才能說 DOMTree 被創建了。
他好像很崩潰,一直在重複著說詞。但心裡想著這根本不可能!這個概念圖壞了。(幫他演內心戲)
太長,懶得讀的答案:瀏覽器會在收到Document(網頁)馬上做 Parsing 的動作
瀏覽器解析(parsing) 引擎爬過了網頁會創建 2 棵樹 (可以配合上面的圖看)
當 Render Tree 被創建的時候,瀏覽器會做進行
最後的流程
瀏覽器是不會停下來等到所有的 HTML 被解析完,意思是說部份的內容會被解析和顯示,直到所有該讀取的內容被讀取完才會結束
附上了兩個圖說明資料真的是馬上讀取
單核
宣染引擎是單核心在工作的,除了網路,結合這樣特性開發者希望他的 <script> 是能馬上被執行的所以出現了這樣的流程
<script> 資源<script> 流程會讓解析HTML的引擎暫停解析直到以上流程結束(javascript 執行完成)。所以把 <script> 放到 <body> 之後是不會增加解析時間,但會提升使用者體驗。
如果使用 <script> API 中的 defer 或 async 是可以提昇解析時間的喔!
HTML Parsing,下載完成會暫停 HTML Parsing,然後執行 javascript code
HTML Parsing,下載完成不會暫停 HTML Parsing,直到解析完成才會執行 javascript
另外瀏覽器是會將放在一起的 <script> 的 src 一起下載的
像是
<script src="/cdn/jquery.1.js" />
<script src="/cdn/jquery.12.js" />
看看 iT邦 的網頁,瀏覽器下載 js 時間是同時間的!(右邊綠色的部分)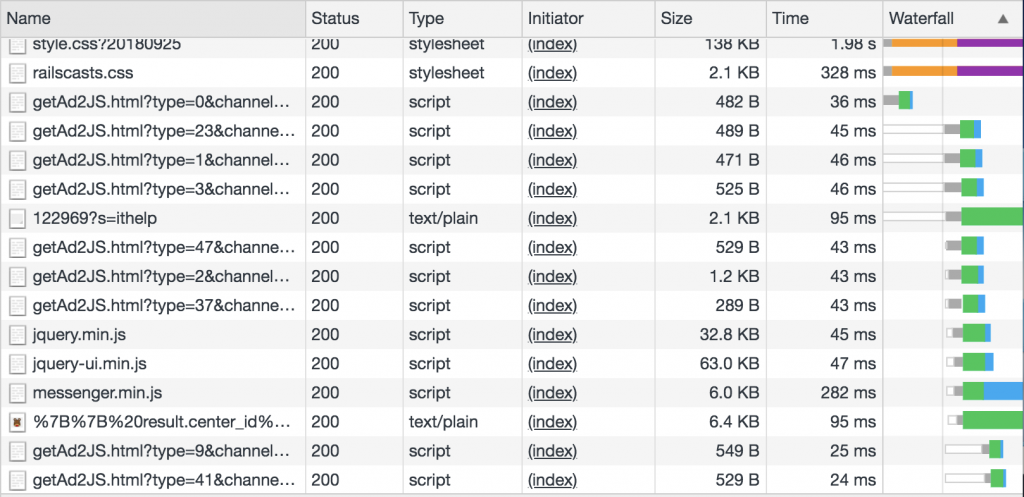
而 HTML 中 jQuery 的部分也是放在一起的~!
不然每次下載完一個 <script /> 在下載另一個是不是很沒效率呢!


 iThome鐵人賽
iThome鐵人賽